The field of robotics has seen incredible advancements over the last few decades, with robots becoming more capable and versatile. These improvements are largely due to better algorithms that allow robots to learn and adapt to complex tasks. Traditionally, teaching a robot to perform a task in the real world has been a complex process, often requiring meticulous manual tuning of simulation parameters and reward functions. This process, known as sim-to-real transfer, is essential for training robots in a simulated environment before deploying them in the real world.
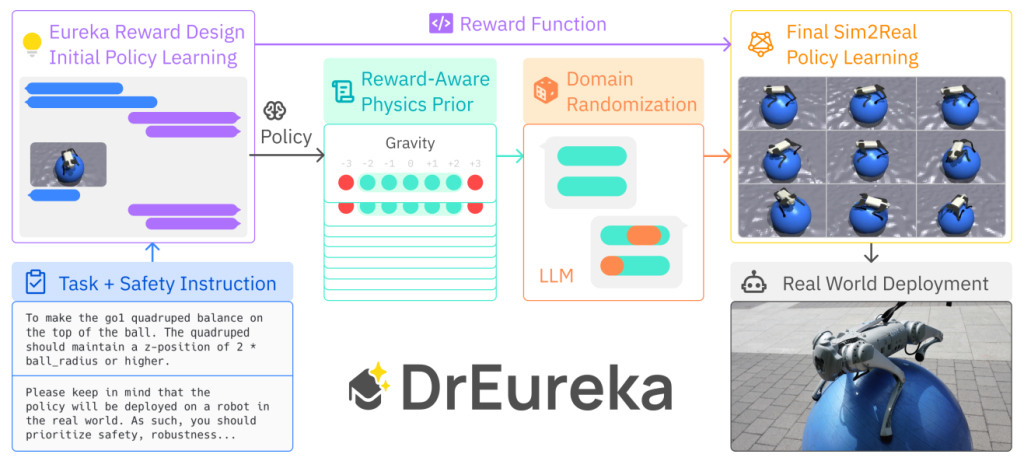
DrEureka marks a major leap in robotics training. How? By using Large Language Models (LLMs) to automate the creation of reward functions and domain randomization parameters: in this way it reduces manual effort and enables robots to learn complex tasks more efficiently and effectively.
Pretty simple, right? Then, if you want something more complicated, go check the following sections:
- Understanding Sim-to-Real Transfer
- DrEureka in Action
- Detailed Exploration of DrEureka’s Mechanisms
- Limitations and Future Work
- Conclusion
Understanding Sim-to-Real Transfer
The Challenge
Sim-to-real transfer involves training a robot in a simulated environment and then transferring the learned behaviors to the real world. The key challenges in this process include:
- Reward Function Design: Defining what a robot should aim to achieve (the “reward”) is crucial. A poorly designed reward function can lead to ineffective or unsafe behaviors.
- Domain Randomization: To ensure that a robot’s training in simulation generalizes to the real world, the simulation must include variability (randomization) in physical parameters like friction and mass. Manual tuning of these parameters is traditionally required and can be very labor-intensive.
DrEureka’s Approach
As explained in its paper, DrEureka introduces an innovative method to address these challenges by using LLMs to automate the creation of reward functions and the tuning of domain randomization parameters. Here’s how it works:
- Automated Reward Function Design: DrEureka uses LLMs to generate reward functions based on the task description and safety considerations, to ensure that the reward function is aligned with the desired task outcome and encourages safe behavior.
- Automated Domain Randomization: DrEureka uses the initial policies to determine suitable ranges for simulation parameters. It then uses LLMs to refine these parameters, ensuring that the robot learns to handle a variety of conditions it might encounter in the real world.
- Efficient Optimization: Instead of searching a vast parameter space, DrEureka strategically narrows down the search using insights generated by LLMs, leading to quicker and more effective training.
DrEureka in Action
Case Studies
DrEureka has been tested on several robotic platforms, demonstrating its versatility and effectiveness across different tasks. Here are two key examples: : quadruped locomotion and cube rotation.
Quadruped Locomotion

- Task Description: The goal is to train a quadruped robot (four-legged) to walk forward at a consistent speed over various terrains.
- Performance: DrEureka-trained policies outperformed human-designed configurations, achieving higher speeds and more consistent performance across different terrains.
- Robustness: DrEureka’s policies proved robust in varied real-world conditions, including artificial grass and different indoor and outdoor settings.
Cube Rotation

- Task Description: A robot hand (anthropomorphic) needs to rotate a cube within its grasp as many times as possible within a time limit.
- Performance: DrEureka again outperformed human-designed methods, with the best policy achieving nearly three times more rotations.
- Consistency: Despite the high variability in performance due to the task’s complexity, DrEureka’s policies generally performed well, demonstrating the model’s ability to handle complex dexterous manipulation tasks.
Technical Breakdown
Eureka Algorithm
The Eureka algorithm is a method designed to automate the generation of reward functions for reinforcement learning (RL) in robotics and other domains. This approach leverages Large Language Models to synthesize reward functions that are both effective and interpretable, based on a given task description. In this way it’s able to significantly streamline the process of designing reward functions, which are critical for guiding the behavior of agents in RL environments.
Reward Function Design
DrEureka builds on the Eureka algorithm but enhances it by incorporating safety instructions into the reward generation process. This inclusion helps induce safer robot behavior, which is crucial for real-world applications. For instance, in quadruped locomotion, DrEureka’s reward function encourages not only forward movement but also penalizes unsafe actions like joint limit violations.
Domain Randomization
DrEureka introduces a novel method called Reward-Aware Physics Prior (RAPP) to determine suitable ranges for domain randomization. This approach evaluates the initial policy under various conditions to identify the parameter ranges that allow the robot to perform effectively. By guiding the LLM with this data, DrEureka ensures that the domain randomization is both effective and efficient.
Results and Analysis
DrEureka’s performance was rigorously tested against traditional human-designed methods. Here are some key findings:
- Improved Performance: DrEureka policies consistently outperformed those designed by humans in terms of speed, distance traveled, and robustness to environmental changes.
- Safety and Adaptability: The inclusion of safety instructions in the reward design process resulted in safer and more reliable robot behavior.
- Efficient Learning: DrEureka’s strategic optimization approach allowed for faster convergence in training, meaning robots learned their tasks more quickly without compromising performance.
Detailed Exploration of DrEureka’s Mechanisms
Reward Function Synthesis
DrEureka’s approach to synthesizing reward functions is a key factor in its success. Here’s a deeper look at this process:
Eureka Algorithm Enhancement
DrEureka extends the Eureka algorithm by incorporating safety directly into the reward design process. This integration allows the model to consider and balance various aspects of the task, such as performance and safety, in a holistic manner.
Process:
- Input Task Description: DrEureka takes a natural language description of the task and safety requirements.
- Generate Reward Functions: Using an LLM, DrEureka samples several potential reward functions.
- Evaluate and Iterate: Each candidate reward function is evaluated by training policies in simulation. Feedback from these training sessions is used to refine the reward functions iteratively.
Example: For quadruped locomotion, a reward function might prioritize moving forward but also penalize excessive torque to prevent damage to robot joints.
Safety Considerations
The safety enhancements in DrEureka’s reward functions help prevent the robot from learning potentially harmful behaviors. This is crucial for ensuring that the robot’s actions are not only effective but also safe for real-world deployment.
- Mechanism: By prompting the LLM to include terms like action smoothness and joint limit penalties, DrEureka ensures that the robot avoids dangerous maneuvers.
- Impact: This approach leads to more robust and stable policies, as demonstrated by the robot’s ability to adapt to different surfaces and avoid harmful actions during testing.
Domain Randomization Strategy
DrEureka’s domain randomization technique is innovative in how it uses machine learning to determine the best parameter ranges for simulation.
Reward-Aware Physics Prior (RAPP)
The RAPP mechanism is designed to fine-tune the simulation parameters based on the initial policy performance, ensuring that the training environment is challenging yet within the capabilities of the robot.
Process:
- Evaluate Initial Policy: DrEureka rolls out the initial policy in simulations with varied physical parameters.
- Determine Feasible Ranges: It identifies which parameter values allow the robot to succeed, setting these as bounds for domain randomization.
- Refine with LLM: The LLM then uses this information to generate precise domain randomization configurations.
Example: If a quadruped robot is slipping too much on a simulated surface, DrEureka might adjust the friction parameters to more realistic levels, ensuring the robot learns to cope with different traction levels.
LLM-Based Sampling
DrEureka uniquely leverages LLMs not just for generating reward functions but also for suggesting domain randomization parameters, making the entire sim-to-real process more coherent and integrated.
- Effectiveness: This method allows DrEureka to propose domain randomization configurations that are more tailored to the learned policies, leading to better performance in varied real-world conditions.
Performance and Results
DrEureka’s effectiveness is best demonstrated through its performance metrics and the robustness of the policies it generates.
Comparative Analysis
- Quadruped Locomotion: DrEureka policies achieved a higher forward velocity and traveled further distances compared to human-designed methods.
| Configuration | Forward Velocity (m/s) | Meters Traveled (m) |
| Human-Designed | 1.32 ± 0.44 | 4.17 ± 1.57 |
| DrEureka (Best) | 1.83 ± 0.07 | 5.00 ± 0.00 |
| DrEureka (Average) | 1.66 ± 0.25 | 4.64 ± 0.78 |
- Cube Rotation: The robot hand managed more rotations within the time limit under DrEureka’s guidance.
| Configuration | Rotation (rad) | Time-to-Fall (s) |
| Human-Designed | 3.24 ± 1.66 | 20.00 ± 0.00 |
| DrEureka (Best) | 9.39 ± 4.15 | 20.00 ± 0.00 |
| DrEureka (Average) | 4.67 ± 3.55 | 16.29 ± 6.28 |
Robustness Tests
DrEureka’s policies were not only more efficient but also demonstrated greater adaptability to environmental changes, maintaining performance across a range of real-world conditions.
- Different Terrains: The quadruped robot equipped with DrEureka’s policies could adapt to artificial grass and varied outdoor terrains, often outperforming the human-designed setups.
Novel Task: The Walking Globe Trick
DrEureka was also employed to teach a quadruped robot a novel, challenging task: walking on a yoga ball, inspired by circus performances. This task tested DrEureka’s ability to generalize and adapt to scenarios not covered during its initial training.

Task Description
- Complex Dynamics: The deformable and unpredictable nature of the yoga ball makes this task particularly challenging. Traditional simulations struggle to model these dynamics accurately, making real-world training essential.
- Task Goal: The robot must balance and walk on the yoga ball for as long as possible, adjusting its movements to maintain stability.
Implementation and Results
DrEureka adapted the simulation environment to include interactions with a movable ball, but with simplified dynamics to keep the task tractable for initial policy training.
- Simulation Training: In simulation, the robot was trained to balance and maneuver on the ball, achieving an average time of 10.7 seconds before falling off.
- Real-World Performance: In a controlled lab setting, with the robot tethered for safety, it managed an impressive average duration of 15.4 seconds on the ball.
| Environment | Time on Ball (s) |
| Simulation | 10.7 ± 5.2 |
| Real World (Lab) | 15.4 ± 4.2 |
- Outdoor Robustness: The policy was further tested in various outdoor scenes, where the robot demonstrated the ability to handle real-world unpredictabilities, such as different terrains and obstacles, effectively showcasing its robustness and adaptability.
Analysis
This task demonstrated several key strengths of DrEureka:
- Rapid Adaptation: DrEureka enabled the robot to quickly learn a completely new and dynamic task, showing the model’s flexibility and the potential to reduce the time needed to develop complex robot behaviors.
- Real-World Efficacy: The successful transition from simplified simulations to challenging real-world conditions highlighted DrEureka’s robust sim-to-real transfer capabilities.
Limitations and Future Work
Despite its impressive capabilities, DrEureka has some limitations that suggest directions for future research:
- Static Domain Randomization Parameters: Currently, the domain randomization parameters are fixed after initial generation. Dynamic adjustment based on ongoing policy performance could potentially yield even better results.
- Lack of Policy Selection Mechanism: DrEureka generates multiple policy candidates but lacks a systematic mechanism to select the most promising one for real-world deployment. Future versions could benefit from incorporating predictive models or heuristics to identify optimal policies based on simulation performance.
Conclusion
DrEureka marks a significant advancement in robotic training methodologies (otherwise I wasn’t here talking about it…). If you’re excited about it, go check this official page about DrEureka.
Concluding, if you liked the article… I’m glad! But, before leaving, here for you some robot dogs on a leash walking on a blue ball.


Leave a comment