
Imagine typing a few lines of text, perhaps a verse from a Tang Dynasty poem or a description of a bustling Hong Kong street market, and watching as a stunningly realistic image materializes on your screen. This is the power of Hunyuan-DiT, a cutting-edge AI model developed by Tencent that excels in generating images from text prompts in English (a normal thing…) and even in Chinese!
Hunyuan-DiT represents a significant leap forward in AI-powered creativity, particularly for those seeking to explore the visual world of Chinese culture. It’s not just about understanding the language; it’s about capturing the nuances, symbolism, and artistic traditions that are deeply embedded within Chinese art and literature.
But, oh, well… The introduction is finished: more details below.
- Understanding the Power of Diffusion Transformers
- The Art of Language: Decoding Text Prompts with CLIP and T5
- Hunyuan-DiT Architecture
- Data: The Fuel for Creativity
- Multi-Turn Dialogue: An Interactive Creative Journey
- Performance: Setting a New Standard
- Beyond the Numbers: Exploring Hunyuan-DiT’s Unique Capabilities
- Open-Source Ecosystem and Future Directions
- Conclusion
Understanding the Power of Diffusion Transformers
At its heart, Hunyuan-DiT is built upon a powerful architecture called a diffusion transformer (a DiT). To grasp its significance, let’s break down the key components:
1. Diffusion Models: Imagine a drop of ink slowly spreading through water. Diffusion models work similarly, gradually adding noise to an image until it becomes pure noise. Then, they learn to reverse this process, starting with noise and progressively removing it to reconstruct the original image. This allows the model to learn the underlying structure and patterns of images.
2. Transformers: Transformers are a type of neural network that excel at understanding sequences, like words in a sentence or pixels in an image. They utilize a mechanism called “attention” to analyze relationships between different parts of the input, allowing them to capture long-range dependencies and complex patterns.
Hunyuan-DiT combines these two powerful concepts, employing a diffusion process within a transformer architecture. This allows it to learn intricate visual details and translate them into high-quality images based on text prompts.
The Art of Language: Decoding Text Prompts with CLIP and T5
Hunyuan-DiT doesn’t just understand words; it decodes the meaning and intent behind them. This is achieved through a unique combination of two powerful text encoders:
CLIP (Contrastive Language-Image Pre-training): CLIP is a model trained to associate images with their corresponding text descriptions. It excels at understanding the overall semantic content of a prompt, grasping the essence of what the user is trying to convey.
T5 (Text-to-Text Transfer Transformer): T5 is a highly versatile language model trained on a massive dataset of text. It excels at understanding nuanced language, including complex sentence structures and subtle references.
Hunyuan-DiT leverages both CLIP and T5, allowing it to understand both the broad strokes and fine details of a text prompt. It’s like having an art historian and a linguist working together to interpret the user’s vision.
Hunyuan-DiT Architecture
Now let’s put every piece together to get this image.
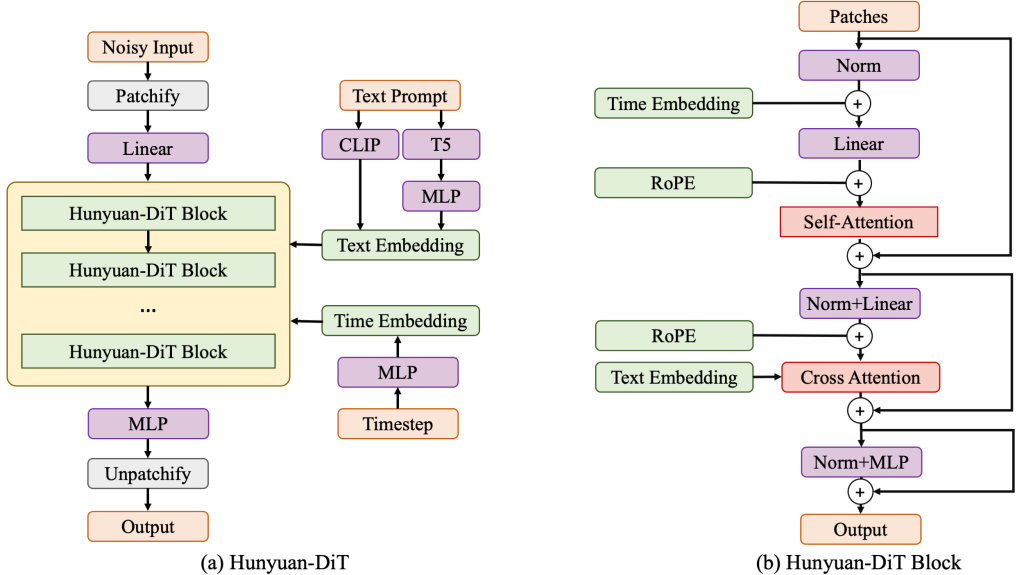
First, a Variational Autoencoder (VAE) compresses the input images into a smaller, more manageable latent space, enhancing efficiency and clarity. This compressed representation is then divided into patches and fed into the diffusion transformer.
The diffusion transformer consists of encoder and decoder blocks that work together to translate the text prompt into a visual representation. Each block contains three key modules: self-attention, cross-attention, and a feed-forward network. Self-attention analyzes relationships within the image, while cross-attention fuses the text encoding from CLIP and T5, guiding the image generation process based on the user’s input.
The Hunyuan-DiT block, specifically, consists of these encoder and decoder blocks. The encoder block processes the image patches, capturing patterns and dependencies, while the decoder reconstructs the image from the encoded information. The decoder also includes a skip module that directly connects to the encoder, facilitating information flow and enhancing detail reconstruction.
Rotary Positional Embedding (RoPE) ensures that the model understands the spatial relationships between image patches, accurately reconstructing the visual composition. Additionally, Centralized Interpolative Positional Encoding enables multi-resolution training, allowing Hunyuan-DiT to handle various image sizes seamlessly.
Also, several techniques, including QK-Norm, layer normalization, and precision switching, ensure the stability and efficiency of the training process, mitigating issues like exploding gradients and numerical errors.
Overall, Hunyuan-DiT’s architecture expertly blends diffusion models and transformer networks to unlock the potential of Chinese text-to-image generation.
Data: The Fuel for Creativity
The quality of an AI model hinges on the data it learns from. Hunyuan-DiT is trained on a massive dataset of images and their corresponding text descriptions, carefully curated and refined to ensure high quality and cultural relevance.
1. Data Categorization: The dataset is meticulously categorized by subject (e.g., people, landscapes, animals), style (e.g., realistic, painting, anime), and even artistic composition. This allows the model to learn a diverse range of visual concepts and cater to different user preferences.
2. Caption Refinement: A crucial step in data preparation involves refining the text captions. Hunyuan-DiT uses a Multimodal Large Language Model (MLLM) to enhance the descriptions, making them more detailed and accurate. This MLLM is also trained to inject world knowledge into the captions, enabling the generation of images with cultural significance and intricate details.
Multi-Turn Dialogue: An Interactive Creative Journey
Hunyuan-DiT goes beyond static image generation, offering a dynamic and interactive creative experience through multi-turn dialogue. Users can start with a basic concept and progressively refine their vision, providing instructions and feedback to the AI along the way.
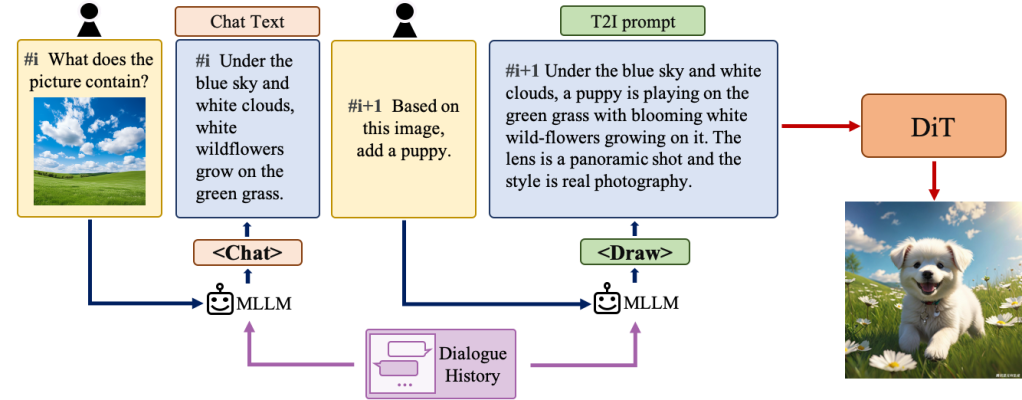
How it works:
- Prompt Enhancement: When a user provides an initial instruction, a specialized MLLM transforms it into a detailed text prompt that the image generation model can understand. This enhancement ensures that the AI grasps the user’s intent, even from simple or abstract descriptions.
- Iterative Refinement: Users can provide further instructions, like “make the background more vibrant” or “add a traditional Chinese dragon to the scene.” The AI incorporates these instructions, generating new images that reflect the evolving vision.
- Subject Consistency: To ensure coherence throughout the dialogue, Hunyuan-DiT incorporates mechanisms to maintain consistency of the main subject across multiple iterations, even as the user requests changes to the background, style, or other details.
Uhm, it’s like having an AI art assistant that collaborates with you, taking your initial sketch and transforming it into a masterpiece through a series of interactive refinements.

Performance: Setting a New Standard
Hunyuan-DiT’s performance has been rigorously evaluated using a comprehensive protocol involving over 50 professional human evaluators.
| Model | Open Source | Text-Image Consistency | Excluding AI Artifacts | Subject Clarity | Aesthetics | Overall |
| SDXL | Yes | 64.3% | 60.6% | 91.1% | 76.3% | 42.7% |
| PixArt-α | Yes | 68.3% | 60.9% | 93.2% | 77.5% | 45.5% |
| Playground 2.5 | Yes | 71.9% | 70.8% | 94.9% | 83.3% | 54.3% |
| SD 3 | No | 77.1% | 69.3% | 94.6% | 82.5% | 56.7% |
| MidJourney v6 | No | 73.5% | 80.2% | 93.5% | 87.2% | 63.3% |
| DALL-E 3 | No | 83.9% | 80.3% | 96.5% | 89.4% | 71.0% |
| Hunyuan-DiT | Yes | 74.2% | 74.3% | 95.4% | 86.6% | 59.0% |
What can we say about this?
- Top Performer among Open-Source Models: Hunyuan-DiT achieves the highest scores across all evaluation metrics (text-image consistency, exclusion of AI artifacts, subject clarity, and aesthetics) when compared to other open-source models.
- Competitive with Closed-Source Models: Hunyuan-DiT demonstrates performance comparable to top closed-source models like DALL-E 3 and MidJourney v6 in terms of subject clarity and aesthetics.
Beyond the Numbers: Exploring Hunyuan-DiT’s Unique Capabilities
1. Understanding Chinese Elements: Hunyuan-DiT excels at generating images containing cultural elements specific to Chinese art and tradition. It can accurately depict traditional clothing, architecture, calligraphy, and even mythical creatures, capturing the symbolism and aesthetic nuances that define these elements.

2. Long Text Understanding: Unlike many text-to-image models, Hunyuan-DiT can comprehend and translate long and detailed text prompts, allowing users to provide rich descriptions and complex scenarios for image generation.

Open-Source Ecosystem and Future Directions
Hunyuan-DiT is not just a research project; it’s an open invitation to the global AI community to collaborate, innovate, and explore the potential of Chinese-focused text-to-image generation.
The official GitHub repository provides access to pre-trained models, inference code, and sample prompts, allowing users to experience Hunyuan-DiT’s capabilities firsthand. To test it without installing anything, there’s also a demo on HuggingFace.
Also, there are upcoming features! In fact, the development roadmap includes plans for:
- Distilled Versions: Smaller, more efficient versions of the model will be released, making it accessible to users with limited computational resources.
- TensorRT Version: Optimized for high-performance inference using NVIDIA GPUs, this version will enable faster and more efficient image generation.
- Training Tools: Tools and resources for training and fine-tuning Hunyuan-DiT will be released, empowering users to customize the model for specific applications or create specialized versions for unique artistic styles.
Nonetheless, it’s crucial to note that Hunyuan-DiT is released under the Tencent Hunyuan Community License Agreement, which includes specific restrictions on commercial use and model improvement, but it’s a lot permissive.
Conclusion
Concluding, Hunyuan-DiT is a nice gem. Its ability to bridge language barriers and unlock the visual world of Chinese culture opens up exciting new possibilities for creators across the globe.
With its open-source nature and ongoing development, Hunyuan-DiT is not just a model; it’s a dynamic platform for collaboration and innovation. It’s an invitation to explore, experiment, and create, reminding us that in the world of AI, imagination is the only limit. And who knows, with Hunyuan-DiT, you might just find your own artistic “zen-sation”!

Leave a comment