As you already know, the world of Large Language Models (LLMs) thrives on processing vast amounts of text data, uncovering hidden patterns to generate human-like text, translate languages, and answer questions with remarkable accuracy. This intricate process relies heavily on a fundamental mathematical operation: Matrix Multiplication (MatMul).
While MatMul has been the cornerstone of LLM architectures, it comes at a significant cost: as LLMs grow larger, encompassing billions of parameters, the computational demands of MatMul become increasingly burdensome! This translates to increased processing time, higher energy consumption, and the need for specialized hardware, limiting accessibility and scalability…
For this reason it has been proposed the MatMul-free Language Model (MatMul-free LM). More details in:
- The Weight of MatMul: Understanding the Bottleneck
- The MatMul-free Solution: Rethinking Efficiency
- Inside the MatMul-free LM: A Closer Look at the Architecture
- Putting MatMul-free LM to the Test: Performance and Efficiency
- Beyond Software: Implementing MatMul-free LM on Custom Hardware
- A Glimpse into the Future: Lightweight LLMs for All
- Conclusion
The Weight of MatMul: Understanding the Bottleneck
Before we explore the MatMul-free LM, let’s first understand why MatMul poses such a significant challenge in traditional LLM architectures.
Imagine an LLM as a vast network of interconnected nodes, each representing a parameter that the model learns during training. These nodes are organized into layers, and the connections between these layers involve multiplying matrices (large grids of numbers) representing the input data and the learned weights of the model.
These MatMul operations are computationally expensive, especially as the size of the matrices grows with larger LLMs and more complex tasks. This demand for computational power translates to:
- Increased processing time: Processing large matrices takes time, slowing down the LLM’s ability to generate text, translate, or answer questions.
- Higher energy consumption: The computational power required for MatMul consumes significant energy, increasing the cost of running and training LLMs.
- Specialized hardware requirements: Efficiently performing MatMul often necessitates specialized hardware like GPUs or TPUs, making LLMs less accessible for researchers and developers without access to such resources.
The MatMul-free Solution: Rethinking Efficiency
The MatMul-free LM tackles these challenges head-on by completely removing MatMul operations from the LLM architecture. Instead of relying on computationally expensive matrix multiplications, it leverages a combination of simpler, more efficient operations:
- Ternary Weights: Instead of storing and processing continuous values, the MatMul-free LM employs ternary weights, which can only take on three values: -1, 0, or +1. This quantization significantly reduces the memory footprint and computational complexity of the model.
- BitLinear Layers: These specialized layers replace the traditional dense layers found in conventional LLMs. By leveraging ternary weights, BitLinear layers transform MatMul operations into simple additions and subtractions, significantly reducing the computational load.
- Element-wise Operations: The MatMul-free LM further reduces complexity by using element-wise operations, where calculations are performed individually on corresponding elements of matrices, rather than on the entire matrices themselves.
Inside the MatMul-free LM: A Closer Look at the Architecture
The MatMul-free LM achieves its remarkable efficiency by redesigning the fundamental building blocks of a traditional LLM.
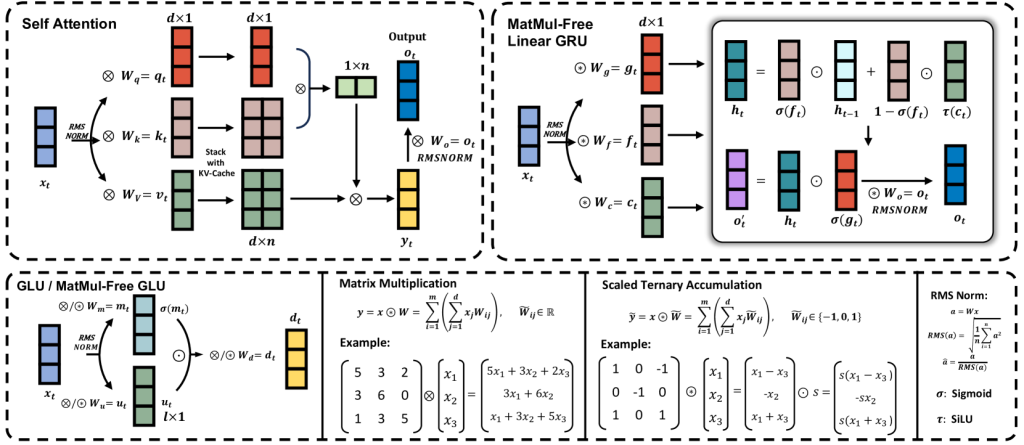
1. MatMul-Free Token Mixer (MLGRU)
Traditional LLMs often employ a mechanism called “self-attention” to understand relationships between words in a sentence. This mechanism, however, relies heavily on MatMul. The MatMul-free LM replaces this with a novel token mixer based on a modified Gated Recurrent Unit (GRU). This MLGRU uses a clever combination of gates and element-wise operations to capture sequential dependencies between words without resorting to MatMul.
2. MatMul-Free Channel Mixer (MatMul-free GLU)
LLMs also need to process information across different dimensions of the input data. The MatMul-free LM achieves this with a channel mixer based on a Gated Linear Unit (GLU), again employing BitLinear layers and element-wise operations to efficiently mix information across channels without MatMul.
The Power of Simplicity:
So, by replacing MatMul with these simpler operations, the MatMul-free LM offers significant advantages:
- Reduced computational cost: Simpler operations translate to less processing power required, making the model faster and more energy-efficient.
- Lower memory footprint: Ternary weights significantly reduce the amount of memory needed to store model parameters.
- Hardware accessibility: The reduced computational and memory demands make the MatMul-free LM deployable on less specialized hardware, potentially making LLMs more accessible to a wider audience.
Putting MatMul-free LM to the Test: Performance and Efficiency
The key question is: how does the performance of this lightweight model stack up against the heavyweights? Extensive experiments show that despite its simpler architecture, the MatMul-free LM punches above its weight class, achieving accuracy comparable to state-of-the-art Transformers, that is the current leading architecture for LLMs. This holds true across a range of language tasks, from predicting the next word in a sentence to answering open-ended questions.
| Model Size | Transformer++ | MatMul-free LM |
| 370M | 41.1% | 40.3% |
| 1.3B | 48.0% | 46.2% |
| 2.7B | 50.7% | 49.9% |
Key Observations:
- Competitive Performance: The MatMul-free LM consistently achieves results close to the Transformer++ baseline, demonstrating its effectiveness despite the absence of MatMul.
- Scaling Advantage: As the models grow larger, the performance difference narrows, suggesting that the MatMul-free architecture might even outperform traditional models at larger scales.
Furthermore, a fascinating trend emerges as these models grow larger. The performance gap between the MatMul-free LM and traditional Transformers shrinks with increasing model size. This suggests that as LLMs continue to evolve and encompass even more parameters, the efficient design of the MatMul-free architecture could very well give it a competitive edge in the future.
Beyond its performance in language tasks, the MatMul-free LM shines when we look at its training efficiency. A clever optimization technique called “Fused BitLinear” significantly speeds up the training process while simultaneously reducing the memory required. This means researchers can train these models faster and with less computational resources.
| Metric | Vanilla BitLinear | Fused BitLinear | Improvement |
| Time (s/iteration) | 1.52 | 1.21 | 25.6% |
| Memory (GB) | 82 | 32 | 61.0% |
(considering a batch size of 28)
Beyond Software: Implementing MatMul-free LM on Custom Hardware
The benefits of the MatMul-free LM extend beyond software implementations. Researchers have successfully deployed this architecture on an FPGA (Field-Programmable Gate Array), a type of customizable hardware, demonstrating its potential for energy-efficient hardware acceleration.
We have:
- Hardware Efficiency: The FPGA implementation highlights the MatMul-free LM’s potential for energy-efficient hardware acceleration.
- Scalability: The results indicate that the architecture can be scaled to multiple cores on the FPGA, further boosting performance.
The FPGA implementation highlights a crucial aspect of the MatMul-free LM: it allows for a more efficient mapping of the model onto hardware, leveraging the architecture’s inherent simplicity to reduce power consumption and increase processing speed.
A Glimpse into the Future: Lightweight LLMs for All
The development of the MatMul-free LM marks a significant leap forward in LLM research. By breaking free from the constraints of MatMul, this innovative architecture can be exploited for:
- More efficient and accessible LLMs: Lightweight models require less computational power and specialized hardware, making them more accessible to researchers and developers with limited resources.
- Faster and more responsive AI: Reduced computational complexity translates to faster processing times, leading to more responsive AI assistants, chatbots, and language translation tools.
- Sustainable AI development: The energy efficiency of MatMul-free models contributes to more sustainable AI development practices, reducing the environmental impact of running and training LLMs.
Conclusion
Is MatMul-free LM the start of a new type of Deep Learning? Who knows, we’ll see!

Leave a comment