
The world of digital content creation is constantly evolving, with a growing demand for personalized and engaging experiences. One area experiencing a surge in popularity is portrait video generation, particularly the ability to generate realistic talking-head videos from a single image. It’s able for example to animate a family photo with a heartfelt message or to bring a historical figure to life with a moving speech… The possibilities are endless.
This is where V-Express comes in, discover about it here:
- Beyond Static Images: The Challenge of Realistic Talking Heads
- Decoding V-Express: A Symphony of Audio and Visual Cues
- The Art of Balance: Progressive Training and Conditional Dropout
- Putting V-Express to the Test: Results and Comparisons
- Looking Ahead: The Future of V-Express
- Conclusion
Beyond Static Images: The Challenge of Realistic Talking Heads
While impressive strides have been made in image generation using diffusion models, producing high-quality portrait videos from single images presents a unique set of challenges… The key lies in achieving a balance between maintaining fidelity to the input image (preserving identity, background, etc.) and incorporating dynamic elements like lip movements, facial expressions, and head poses that synchronize with the provided audio.
Traditional methods often struggle to find this balance, resulting in videos that either appear unnatural and robotic or fail to maintain consistency with the original image. V-Express, described in its paper, tries to overcome these issues introducing a robust framework that harmonizes diverse control signals to produce compelling and realistic talking-head videos.
Decoding V-Express: A Symphony of Audio and Visual Cues
As a starting point, V-Express utilizes a Latent Diffusion Model (LDM): a powerful generative model that operates in a compressed latent space for efficient image synthesis. This LDM, built upon the Stable Diffusion v1.5 architecture is responsible for generating individual video frames.
Think of an LDM like a skilled sculptor who works with digital clay. Instead of directly manipulating pixels in an image, LDMs operate in a compressed “latent” space. Here’s a simplified breakdown:
- Encoding: The input image (your reference portrait) is first compressed into a smaller, more abstract representation called a “latent” code. Imagine squeezing a complex sculpture into a small box.
- Diffusion: This latent code is then gradually corrupted by adding noise, like our sculptor slowly obscuring the details of the sculpture until it becomes an unrecognizable blob.
- Reverse Diffusion and Guidance: Now, the magic happens! The LDM learns to reverse this noise process, starting from pure noise and progressively refining it back into a coherent image. The key here is that during this denoising process, the LDM can be guided by various control signals (the audio, reference image features, and pose information).
- Decoding: Finally, the refined latent code is decoded back into a full image: our talking head, complete with synchronized lip movements, expressions, and poses.
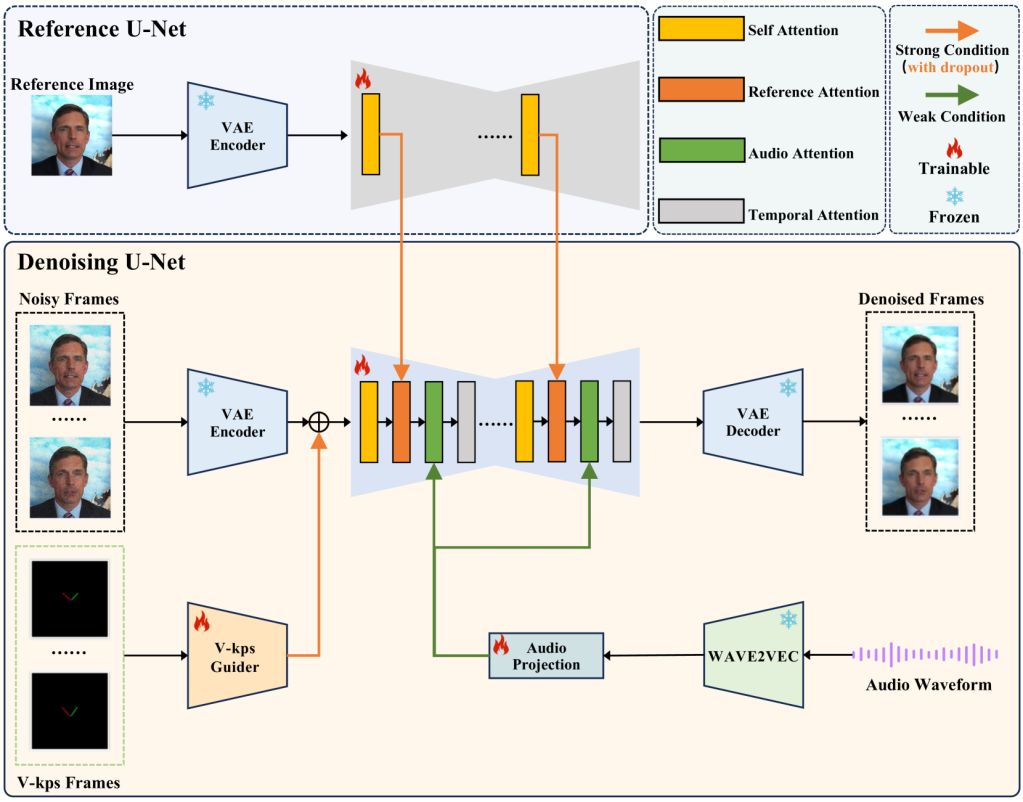
Now, imagine V-Express as a sophisticated film studio, with different departments working together to create the final product. At its heart is the Denoising U-Net, a powerful image generator that takes in a noisy, blurry sketch of a video frame and progressively refines it based on the instructions it receives from other specialized modules. It’s like a master artist working with the “digital clay” of the latent space.
But even the best artists need guidance. That’s where the four key Attention Layers within the U-Net come in:
- Self-Attention: This layer helps the U-Net understand the spatial relationships within each frame. Imagine it as the artist carefully studying the proportions and details of the face they’re drawing.
- Reference Attention: This layer acts as the art director, constantly referring to the input reference image to ensure the generated face stays true to the original person’s likeness, background, and overall style.
- Audio Attention: Now, we’re bringing in the voice actors! This layer listens closely to the provided audio and guides the U-Net to create lip movements that sync up perfectly with the words being spoken.
- Motion Attention: Finally, we have the choreographer, ensuring the movements between frames are smooth and natural. This layer analyzes the temporal relationships between frames, preventing jerky motions and maintaining a coherent flow.
Beyond the U-Net: Specialized Studios
In addition to the core U-Net, V-Express has three dedicated “studios” that preprocess and refine different aspects of the input:
- ReferenceNet: The Identity Preservers
- Their mission: Capture the essence of the input reference image – the person’s unique features, the background scenery – everything that makes the image distinct.
- How they do it: They use a network similar to the U-Net itself, but instead of generating images, they extract a detailed “style guide” from the reference image. This guide is then passed on to the Denoising U-Net’s Reference Attention Layer.
- V-Kps Guider: The Movement Coaches
- Their mission: Direct the overall positioning and movement of the face – head turns, subtle tilts, and even blinking.
- How they do it: Instead of working with complex facial landmarks, they use simplified “V-Kps” images, which are like minimalist sketches of the face with just the eyes and nose. This allows for precise control over pose without interfering with the Audio Attention Layer’s job of animating the mouth.
- Audio Projection: The Lip-Sync Specialists
- Their mission: Transform the raw audio into a format the Denoising U-Net can understand and use to create natural-looking lip movements.
- How they do it:
- Audio Conversion: They first use a pre-trained audio encoder (Wav2Vec2) to convert the audio into a sequence of numerical representations called embeddings. Think of these like musical notes on a sheet, capturing the different sounds and their timing.
- Temporal Alignment: They then carefully synchronize these audio notes with the corresponding video frames.
- Context is Key: To make the lip movements extra realistic, they analyze the audio “notes” before and after each frame, capturing the subtle ways our mouths prepare for and transition between sounds.
- Q-Former Magic: Finally, they use a special neural network called a Q-Former to process this contextually enriched audio information and send it to the U-Net’s Audio Attention Layer.
So, V-Express’s architecture is a carefully orchestrated collaboration between different modules. Each module plays a crucial role in transforming raw inputs into a symphony of synchronized audio and visuals, resulting in a talking-head video that’s both realistic and engaging.
The Art of Balance: Progressive Training and Conditional Dropout
One of the key innovations of V-Express lies in its approach to handling control signals of varying strengths. Audio signals, often weaker than visual cues like reference images and pose information, can easily be overshadowed during the generation process. To address this, V-Express implements two crucial techniques:
- Progressive Training: This strategy involves training the model in stages, gradually introducing and emphasizing weaker signals to ensure they are effectively learned and incorporated. The training progresses from single-frame generation focusing on visual consistency to multi-frame generation, where audio-driven lip synchronization and temporal coherence are prioritized.
- Conditional Dropout: This technique prevents the model from over-relying on stronger signals by randomly “dropping out” or ignoring specific inputs during training. For example, the model might randomly disregard the reference image or V-Kps information for certain frames, forcing it to rely more heavily on the audio input for guidance. This ensures that the model learns to effectively utilize all available signals, preventing any single signal from dominating the generation process.
Putting V-Express to the Test: Results and Comparisons
V-Express has been rigorously evaluated on benchmark datasets, demonstrating its prowess in generating high-quality talking-head videos that surpass existing methods in several aspects.
Quantitative Evaluation:
To see how well V-Express performs, it has been compared with two other methods, Wav2Lip and DiffusedHeads. The “goodness” of a talking-head video has been measured with a combination of metrics that assess different aspects:
- Video and Image Quality:
- FID (Fréchet Inception Distance): This metric is like a sensitive nose sniffing out differences between real and generated images. Lower FID scores mean the generated images look more realistic.
- FVD (Fréchet Video Distance): Similar to FID, but specifically for videos. It checks how natural the overall video looks, including the flow of motion.
- Staying True to the Original:
- ΔFaceSim: This measures how well the generated face in the video matches the person in the original reference image. It calculates the difference in facial similarity between a real video of the person talking and the generated video. Lower scores are better here.
- Moving in Sync:
- KpsDis (Keypoint Distance): Imagine tiny dots tracking the movement of facial features. This metric checks how closely the generated face’s movements align with the target poses we set.
- SyncNet: This specifically focuses on how well the lip movements match the audio. Think of it like a judge at a lip-sync battle.
The datasets used for the evaluation are TalkingHead-1KH and AVSpeech datasets, both collections of videos designed specifically for training and evaluating talking-head generation models, but with some key differences:
TalkingHead-1KH Dataset:
- Focus: This dataset prioritizes high-quality, diverse talking-head videos.
- Resolution: It features videos with a resolution of 1024×1024 pixels, contributing to its high visual fidelity.
- Diversity: The dataset includes a wide range of individuals, head poses, facial expressions, and speaking styles, making it suitable for training robust models.
- Use Cases: TalkingHead-1KH is commonly used for tasks like:
- Training high-fidelity talking-head generation models.
- Evaluating the realism and visual quality of generated videos.
- Benchmarking new methods against state-of-the-art approaches.
AVSpeech Dataset:
- Focus: This dataset emphasizes large-scale, in-the-wild talking-head data.
- Source: It comprises a vast number of videos sourced from YouTube, reflecting real-world conditions and variations.
- Challenges: Due to its in-the-wild nature, AVSpeech presents challenges like:
- Variable video quality and resolution.
- Background noise and distractions.
- Variations in lighting and camera angles.
- Use Cases: AVSpeech is well-suited for training models that need to be:
- Robust to real-world conditions and variations.
- Capable of handling diverse speaking styles and accents.
- Less reliant on pristine, studio-quality input data.
Both datasets serve valuable purposes in advancing the field of talking-head generation, offering researchers and developers diverse training and evaluation resources to push the boundaries of what’s possible.
TalkingHead-1KH Dataset Results
| Metric | Wav2Lip | DiffusedHeads | V-Express |
| FID | 29.06 | 115.41 | 25.81 |
| FVD | 250.95 | 344.69 | 135.82 |
| ΔFaceSim | 10.77 (91.46) | / | 3.63 (84.32) |
| KpsDis | 41.60 | / | 3.28 |
| SyncNet | 6.890 | / | 3.480 |
AVSpeech Dataset Results
| Metric | Wav2Lip | DiffusedHeads | V-Express |
| FID | 26.71 | 104.61 | 23.38 |
| FVD | 251.40 | 363.10 | 117.93 |
| ΔFaceSim | 7.28 (91.84) | / | 0.28 (84.84) |
| KpsDis | 42.93 | / | 2.78 |
| SyncNet | 6.623 | / | 3.793 |
We can see that V-Express consistently outperforms other methods in generating realistic and well-aligned talking-head videos. While its lip-syncing accuracy is competitive, it truly shines in preserving the subject’s identity, accurately following facial pose guidance, and producing natural-looking video quality overall.
Qualitative Results: V-Express generates visually compelling videos with natural lip movements and facial expressions that are synchronized with the provided audio. The generated videos maintain high fidelity to the input reference image, preserving the subject’s identity and background details.

Beyond Numbers: The Advantages of V-Express
- Enhanced Control and Flexibility: V-Express provides users with fine-grained control over various aspects of the generated videos. From adjusting the influence of the reference image and audio to controlling the intensity of lip movements, users can fine-tune the output to achieve their desired artistic vision.
- High-Quality Output: V-Express generates high-fidelity videos with impressive visual quality and smooth, natural-looking animations. The combination of progressive training and conditional dropout ensures a harmonious balance between different control signals, resulting in realistic and engaging talking-head videos.
- Wide Range of Applications: The potential applications of V-Express are vast and diverse. It can be used to create personalized avatars for virtual reality, generate engaging marketing and educational content, breathe life into historical figures for documentaries, and much more.
Looking Ahead: The Future of V-Express
While V-Express represents a significant leap forward in audio-driven portrait video generation, the journey doesn’t end here. Future research directions include:
- Multilingual Support: Expanding language support beyond English to encompass a wider range of languages will broaden the accessibility and applicability of V-Express.
- Reducing Computational Burden: Improving the efficiency of the model will make it more accessible for users with limited computational resources, allowing for faster generation times and a smoother user experience.
- Explicit Control over Facial Attributes: Introducing more explicit controls over specific facial attributes, like hair color, facial hair, and age, will provide users with even greater creative freedom.
Conclusion
Concluding, I’d like to emphasize that its code is for both academic and commercial use, while the models are for academic use only. Nonetheless, V-Express has a great role for a new era of personalized and engaging video content creation, empowering users to bring static portraits to life with expressive and realistic animations, unlocking a world of possibilities for creative expression and communication!

Leave a comment