
Stable Diffusion, spearheaded by Stability AI, has become synonymous with accessible and powerful AI image generation. With the release of Stable Diffusion 3 (SD3) the bar for open-source text-to-image generation has been significantly raised. Also, yesterday the weights of Stable Diffusion 3 Medium have been released on Hugging Face, so… It’s time for an article!
- Unveiling the Powerhouse: The Architecture of SD3
- SD3 Medium: The Model For Everyone
- Open Access, Collaboration, and Responsible AI: The SD3 Ethos
- Conclusion
Unveiling the Powerhouse: The Architecture of SD3
At the heart of SD3’s capabilities lies its sophisticated architecture, a finely tuned system meticulously crafted for efficiency and high-fidelity image generation, described on its paper.
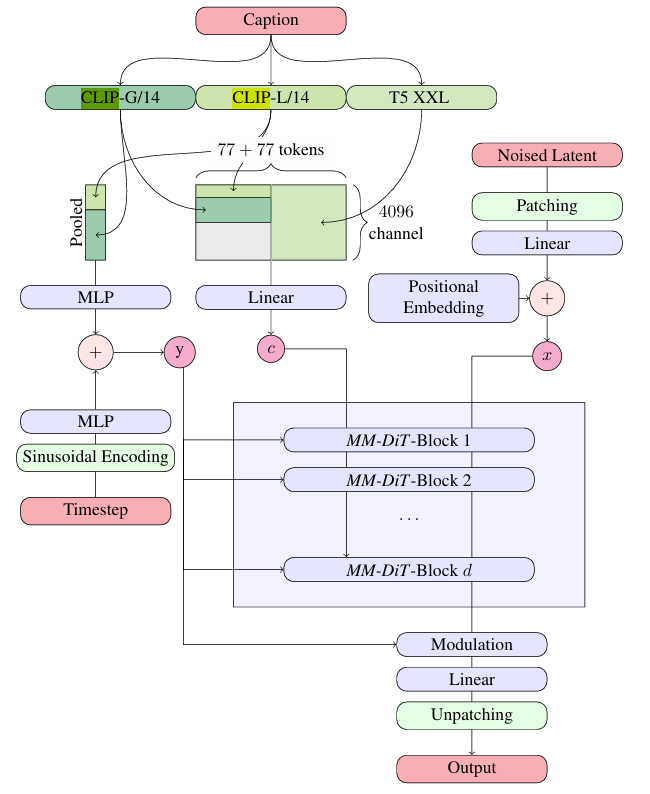
Let’s break down the key components that work in concert to produce stunning visuals from text prompts.
1. Preprocessing: Laying the Groundwork
Before the magic of image generation can unfold, SD3 preprocesses both image and text data into formats optimized for its core engine. This critical initial stage ensures efficient training and inference.
Image Representation: The Autoencoder’s Role
SD3 leverages the power of a pretrained autoencoder to handle image data. This autoencoder comprises two key components:
- Encoder (E): This component takes the input image (e.g., a high-resolution photograph) and compresses its information into a lower-dimensional representation called the latent space. This latent space captures the essence of the image in a compact form.
- Decoder (D): The decoder performs the reverse operation, taking the latent representation and reconstructing it back into a full-resolution image.
Why use an autoencoder? Processing high-resolution images directly is computationally expensive. By compressing images into a smaller latent space, SD3 can train and generate images more efficiently while preserving crucial visual details. SD3 utilizes a downsampling factor of 8 (meaning the latent space dimensions are 8 times smaller than the original image) and an enhanced 16-channel latent space for richer image representation, contributing to the model’s impressive realism, especially in complex areas like hands and faces.
Text Representation: Encoding Meaning and Style
SD3 employs not one but three pretrained text encoders working in unison to extract a nuanced understanding of the input text prompt:
- Two CLIP Models: These models (CLIP L/14 and OpenCLIP bigG/14) excel at capturing the semantic meaning of the prompt and its relationship to visual concepts.
- One T5-XXL Model: This model specializes in understanding language structure and grammatical relationships, proving particularly beneficial for generating text within images.
The outputs from these encoders are combined into two distinct representations:
- Pooled Representation (cvec): This is a condensed representation capturing the overall semantic and stylistic essence of the prompt.
- Contextual Representation (cctxt): This representation preserves the sequence of words and their relationships within the prompt, crucial for tasks like coherent text rendering.
2. Multimodal Diffusion Transformer (MMDiT): The Core Engine
The true innovation of SD3 lies in its Multimodal Diffusion Transformer (MMDiT) architecture. This novel backbone is designed to effectively handle the interplay between the encoded image and text information, making it a significant departure from traditional diffusion models.
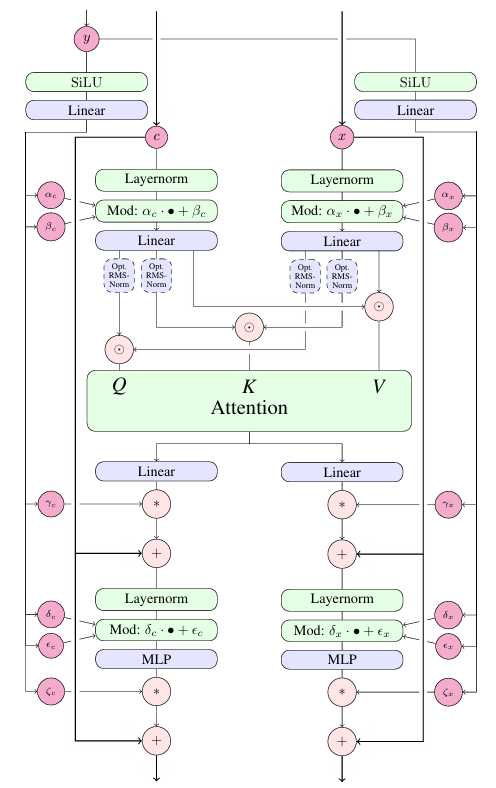
Transformer Architecture: Embracing Parallelism
MMDiT, as its name suggests, leverages the power of transformers. Unlike traditional recurrent networks that process data sequentially, transformers analyze entire sequences in parallel, significantly accelerating training and inference.
Multimodal Fusion: Bridging Text and Images
The “multimodal” in MMDiT highlights its strength: the ability to process and fuse information from different modalities (in this case, text and images). It achieves this through a clever combination of:
- Sequence Concatenation: The encoded image patches (from the autoencoder’s latent space) and the text tokens (from the text encoders) are cleverly combined into a single sequence, allowing the transformer to analyze them in context.
- Dual Attention Mechanism: Instead of using a single set of weights for all data, MMDiT employs two separate sets of weights: one for image data and one for text data. This allows the model to learn specialized representations for each modality while still enabling cross-modal interaction.
The Building Blocks of MMDiT
MMDiT is built using a series of repeating blocks, each comprising:
- Layer Normalization: This normalizes the input data, stabilizing and accelerating the training process.
- Multi-Head Attention: This is the heart of the transformer, allowing the model to weigh the importance of different parts of the input sequence (both image and text) in relation to each other. MMDiT uses separate attention heads for image and text, enabling focused within-modality processing while maintaining a mechanism for cross-modal information exchange.
- Feedforward Networks: These networks apply further non-linear transformations to the output of the attention mechanism, increasing the model’s ability to learn complex relationships in the data.
3. Rectified Flow (RF): From Noise to Image
SD3 uses a Rectified Flow (RF) formulation to generate images. This mathematical framework dictates how the model gradually transforms random noise into a coherent image guided by the input text prompt and the learned representations.
Straight-Line Diffusion: Enhancing Efficiency
Traditional diffusion models often involve complex, curved paths in their transformation from noise to image. RF, however, enforces straight-line diffusion paths, leading to more efficient sampling and requiring fewer steps to generate high-quality images.
Logit-Normal Timestep Sampling: Focusing on the Details
SD3 further enhances its training by employing logit-normal timestep sampling. Instead of uniformly sampling points along the diffusion path, this method focuses more on the intermediate steps where the model refines details, leading to improved image quality and faster convergence.
SD3 Medium: The Model For Everyone
SD3 is a family of models, ranging from 800 million parameters to 8 billion parameters. SD3 Medium, with its 2 billion parameters, is one of these models: its aim is to strike a balance between power and efficiency, being designed to be powerful enough for professional use while remaining accessible to individuals with consumer-grade hardware. However, it’s not so good with texts, given that it’s unable to write down “stable diffusion 3” correctly:


Open Access, Collaboration, and Responsible AI: The SD3 Ethos
Beyond the technical prowess, SD3 and SD3 Medium in particular represent a commitment to democratizing AI and promoting responsible development:
- Open Weights and Licensing: SD3 Medium’s weights are open-source for non-commercial use, encouraging experimentation and community-driven development. Commercial licenses are available for professionals and businesses.
- Industry Collaboration: Partnerships with NVIDIA and AMD ensure optimal performance across a wide range of hardware, maximizing accessibility.
- Safety and Bias Mitigation: Stability AI prioritizes safety through rigorous data filtering and ongoing research to mitigate potential biases and risks associated with AI image generation.
Conclusion
Concluding, here for you the Hugging Face Space to try to create something with SD3 Medium… Have fun!


Leave a comment