
Large Language Models (LLMs) have revolutionized the AI landscape with their ability to generate human-quality text, translate languages, and answer complex questions. However, their tendency to “hallucinate”, that is to generate plausible-sounding but factually incorrect information, remains a significant hurdle to their widespread adoption in critical applications.
Lamini Memory Tuning emerges as a potential game-changer, promising to drastically improve the factual accuracy of LLMs and reduce hallucinations to unprecedented levels. And with this the introduction is finished. For the curious, more details in:
- The Accuracy Imperative: Why Current LLMs Fall Short
- Unveiling Lamini Memory Tuning: A Paradigm Shift in LLM Training
- Unlocking Precision: How Lamini Memory Tuning Works
- Lamini Memory Tuning in Action: Real-World Applications
- Reshaping the LLM Landscape: The Promise of Lamini Memory Tuning
- The Road Ahead: Navigating the Future of Factual AI
- Conclusion
The Accuracy Imperative: Why Current LLMs Fall Short
While LLMs excel at mimicking human language patterns, their inherent design often leads them astray when it comes to factual accuracy… In fact, trained on massive datasets of text and code, these models learn to predict the most statistically likely sequence of words, not necessarily the factually correct ones.
This probabilistic approach often results in:
- Inaccuracies in Specific Facts: LLMs might stumble on details like dates, names, or technical specifications, blurring them with similar but incorrect information learned during training.
- Hallucinations: In their quest for fluency, LLMs can inadvertently fabricate information, presenting it with unwavering confidence despite its lack of factual basis.
Existing techniques like prompting and Retrieval Augmented Generation (RAG) have attempted to address these limitations by providing LLMs with relevant external information. While beneficial, these approaches often prove insufficient in completely eliminating hallucinations, as the models still struggle to discern between closely related but ultimately incorrect options.
Unveiling Lamini Memory Tuning: A Paradigm Shift in LLM Training
Lamini Memory Tuning takes a fundamentally different approach to fine-tuning LLMs, shifting the focus from minimizing average error across a vast dataset to achieving near-zero error on specific facts. This innovative method empowers LLMs to recall critical information with remarkable precision without compromising their ability to generalize and perform well on a broader range of tasks.
Unlocking Precision: How Lamini Memory Tuning Works
Imagine you’re tasked with building a super-intelligent AI assistant, capable of accessing and processing information with perfect accuracy. You wouldn’t simply stuff its “brain” with an endless stream of data, hoping it somehow remembers every single detail with perfect clarity. Instead, you’d need a more organized and efficient approach. This is precisely the philosophy behind Lamini Memory Tuning’s architecture.
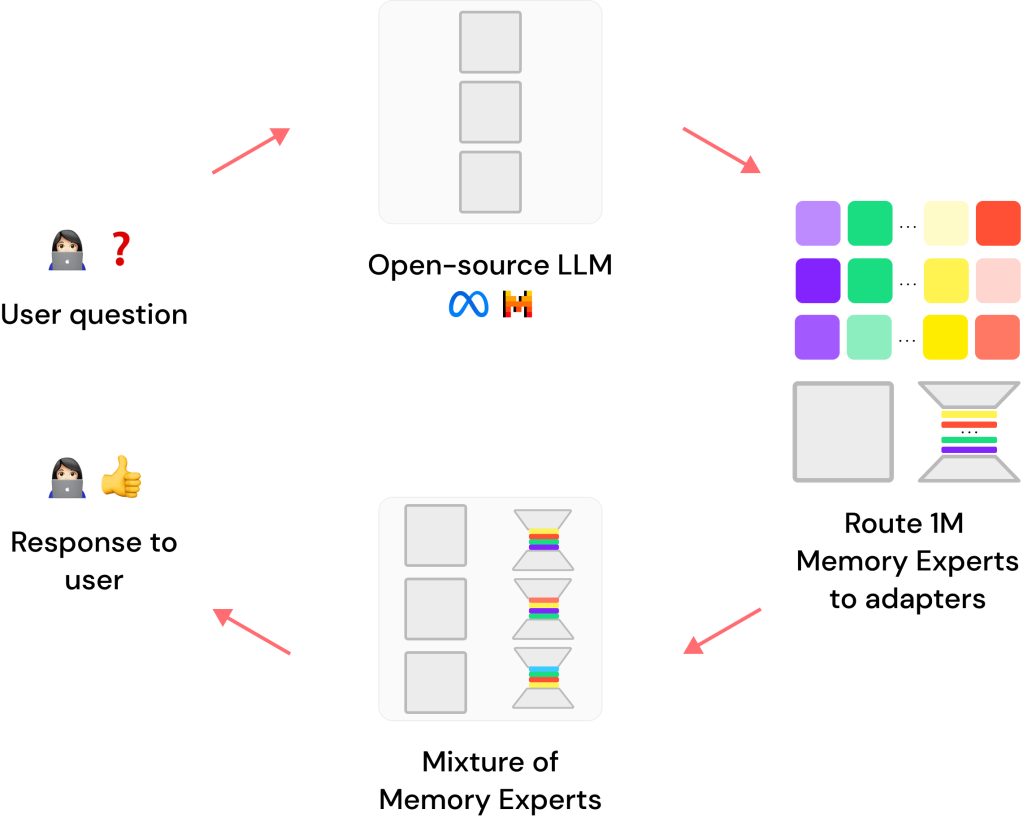
1. The Foundation: A General-Purpose LLM
At the heart of Lamini Memory Tuning lies a pre-trained, open-source foundation LLM. Think of this as the AI’s “core brain,” providing it with fundamental language processing abilities (understanding grammar, recognizing patterns, and generating human-like text). However, this core LLM, while generally knowledgeable, isn’t designed for perfect factual recall. It’s like having a vast library but no card catalog: you can find information, but it might take a while, and accuracy isn’t guaranteed.
2. The Specialists: A Mixture of Memory Experts (MoME)
This is where Lamini Memory Tuning diverges from traditional methods. Instead of modifying the entire foundation LLM, it introduces a network of specialized “memory experts.” Imagine these experts as a collection of meticulously organized, highly focused encyclopedias, each dedicated to a specific domain of knowledge: one expert might be dedicated to historical events, another to scientific facts, and yet another to financial data.
These experts are not simply “bolted on” to the foundation LLM. Instead, they’re integrated through a technique called LoRA (Low-Rank Adaptation). Think of LoRA as creating a series of “shortcuts” within the LLM’s neural pathways. These shortcuts don’t alter the core knowledge but allow the model to rapidly access and process specific information stored within each memory expert.
3. The Navigator: Dynamic Expert Router
Now, imagine having thousands, even millions, of these specialized memory experts. Navigating such a vast knowledge base efficiently is crucial. This is where the Dynamic Expert Router comes in. Think of the router as a highly efficient librarian. When the AI receives a query, the router analyzes it, identifies the relevant domain(s) of knowledge, and activates only those memory experts containing the necessary information.
This dynamic selection process ensures that the AI doesn’t waste time sifting through irrelevant data. It’s like having the librarian instantly direct you to the precise page in the correct encyclopedia, ensuring quick and accurate responses.
We understand better with an example:
Let’s say you ask the AI “What is the capital of France?”. The Dynamic Expert Router recognizes this as a geography question. It activates the memory expert specializing in world capitals. This expert, having been specifically trained on geographical data, instantly provides the correct answer: “Paris”. The foundation LLM then integrates this information into a natural language response.
Lamini Memory Tuning in Action: Real-World Applications
Early adopters of Lamini Memory Tuning, that are Fortune 500 companies, are already witnessing its transformative potential across various use cases:
| Use Case | Challenge | Result with Lamini |
| Text-to-SQL | Democratizing data access by translating natural language questions into SQL queries for databases with unique naming conventions and complex schemas. | Achieved 95% accuracy compared to 50% with traditional RAG approaches. |
| High-Precision Classification | Automating data labeling with high accuracy to save time and resources. | Achieved 100% accuracy across thousands of documents classified into 900 specific categories. |
| Product Recommendations | Enhancing e-commerce experiences with AI-powered product suggestions that are accurate and reliable. | Achieved 88% accuracy in recommending products from a database of 50,000 items, eliminating errors in product IDs. |
Reshaping the LLM Landscape: The Promise of Lamini Memory Tuning
Lamini Memory Tuning signifies a paradigm shift in how we approach LLM training and deployment, offering several advantages over existing methods:
- Unprecedented Accuracy: By targeting near-zero error on specific facts, Lamini Memory Tuning empowers LLMs to achieve remarkable accuracy levels, enabling their use in applications where precision is paramount.
- Reduced Hallucinations: The specialized training and index-based retrieval system significantly minimizes the likelihood of the LLM hallucinating information, making its responses more reliable and trustworthy.
- Enhanced Efficiency: The ability to selectively activate memory experts at inference time translates to faster response times and reduced computational costs compared to activating the entire model for every query.
- Scalability: The MoME architecture allows for the integration of vast amounts of factual data, making Lamini Memory Tuning particularly well-suited for knowledge-intensive applications.
The Road Ahead: Navigating the Future of Factual AI
Lamini Memory Tuning is a huge step forward in the quest for accurate and reliable AI systems. However, challenges remain:
- Defining “Facts”: Establishing clear criteria for what constitutes a “fact” and ensuring the accuracy and objectivity of the information stored within memory experts is crucial.
- Bias Mitigation: Like all AI systems, Lamini Memory Tuning is susceptible to biases present in the training data. Mitigating these biases and ensuring fairness in the model’s outputs will be an ongoing area of focus.
- Explainability and Trust: As LLMs become increasingly accurate and integrated into critical decision-making processes, understanding how they arrive at their conclusions and building trust in their outputs will be essential.
Conclusion
So, there you have it: Lamini Memory Tuning. It’s like giving an LLM a super-caffeinated brain boost, but instead of jittery anxiety, it gets a PhD in remembering stuff. So, no more awkward replies from your AI assistant about the capital of France or, more likely, about glue to add to your pizza!

Leave a comment