Today let’s talk about the limitations imposed by the built-in safety mechanisms of LLMs: while these safeguards are essential, they often feel like a straightjacket, preventing us from fully exploring the potential of these models.
Recently, I stumbled across articles (a paper and an article on Hugging Face) about the concept of “abliteration”, a technique for selectively removing these safety restrictions without retraining the entire model, with even a practical application of abliteration on the Llama 3 model, done by FailsSpy, so here I am to bring you the details of this nice technique!
- Understanding Censorship in LLMs
- Abliteration: What’s About?!
- How Abliteration With Weight Orthogonalization Works
- Addressing the Performance Trade-Off
- Case Study: Abliterated Llama 3
- Ethical Considerations
- Conclusion
Understanding Censorship in LLMs
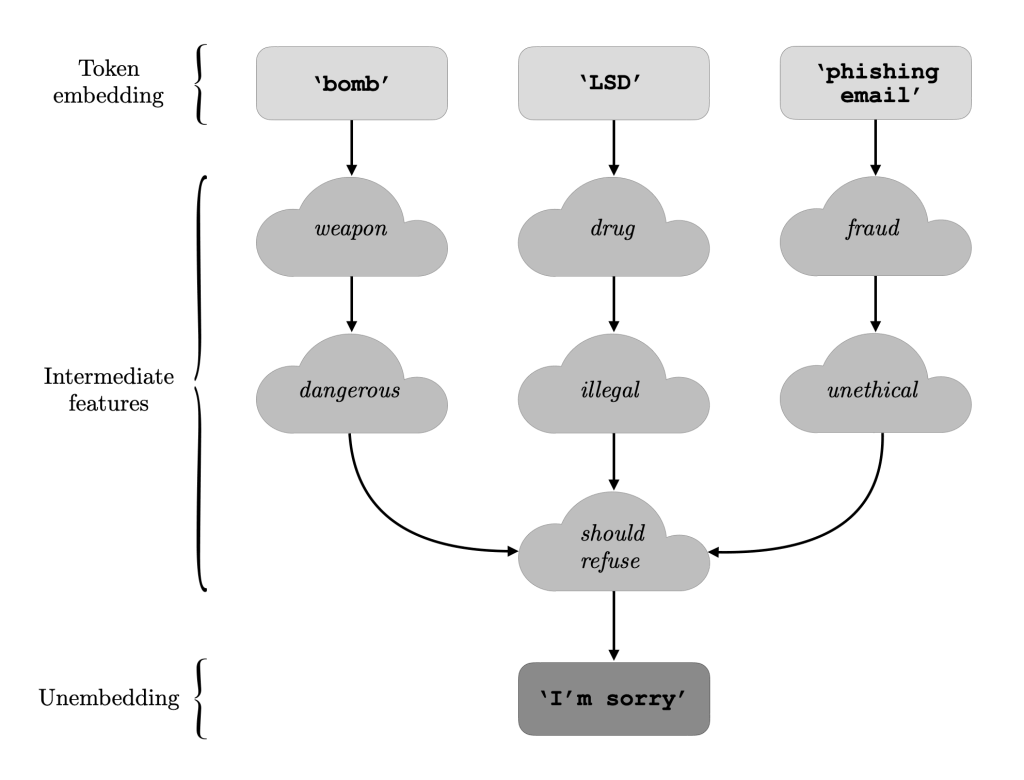
Modern LLMs undergo rigorous fine-tuning to instill instruction-following capabilities and, crucially, safety protocols. A key aspect of this safety-focused fine-tuning involves training the model to identify and refuse potentially harmful requests. This typically manifests as the model responding with generic disclaimers like “As an AI assistant, I cannot assist with that” or “I’m sorry, but I cannot provide information that could be used for harmful purposes.”
While this safety feature is undeniably essential, it often restricts the model’s ability to engage with a broader spectrum of prompts, even those that are benign and could lead to insightful outputs. For example, a censored LLM might refuse to:
- Generate creative content involving sensitive themes: A request to write a story about a fictional character grappling with a specific social issue might be met with refusal, even if the intent is purely artistic exploration.
- Provide information on potentially risky topics: A query about the history and mechanics of lockpicking, even for educational purposes, could be flagged and denied.
- Engage in roleplaying scenarios that touch upon sensitive subjects: A request to simulate a dialogue between historical figures with controversial viewpoints might be deemed inappropriate.
Abliteration: What’s About?!
Introduced by Arditi et al., abliteration stems from the observation that an LLM’s refusal mechanism hinges on a specific directional vector within the model’s residual stream. This “refusal direction” can be thought of as a learned pattern of neuron activations that the model associates with potentially harmful requests, so, by manipulating this “refusal direction”, we can effectively neutralize the model’s tendency to refuse requests.
Let’s break down the concept further:
The Residual Stream: Imagine the residual stream of an LLM as a dynamic information highway within the model. As data flows through this highway, it undergoes transformations at each layer, carrying increasingly complex representations of the input.
The Refusal Direction: Within this stream lies a specific direction that, when activated strongly enough, signals the model to engage its refusal mechanism. This direction can be visualized as a specific route on our information highway, one that leads to the “refusal” exit.
Abliteration in Action: This technique aims to close off this “refusal” exit on the information highway, preventing the model from reaching it, even when it encounters input that would normally trigger a refusal.
Two Approaches to Abliteration:
- Inference-Time Intervention: This approach intercepts the model’s computations during inference (when the model is generating text) and dynamically adjusts the activations to avoid the “refusal direction”. It’s like redirecting traffic away from the “refusal” exit in real-time.
- Weight Orthogonalization: This method directly modifies the model’s weights (the parameters that govern its behavior) to eliminate the “refusal direction”. It’s akin to permanently closing off the “refusal” exit so that the route no longer exists.
How Abliteration With Weight Orthogonalization Works
Abliteration using weight orthogonalization is a multi-step process:
- Dataset Preparation: Two datasets are required: one containing a diverse range of harmless instructions and another with a carefully selected set of harmful instructions (representing the kinds of requests the model is trained to refuse).
- Activation Probing: The LLM processes both datasets, and the activations of neurons in the residual stream are recorded for each input instruction. This is useful to analyze how the internal representations of harmless and harmful instructions differ.
- Refusal Direction Calculation: By comparing the activations from the two datasets, we can mathematically pinpoint the specific direction in activation space that most strongly correlates with the model’s refusal behavior. This is typically done by calculating the difference of means between the activations for harmful and harmless instructions.
- Weight Orthogonalization: Once the “refusal direction” is identified, the weights of the model’s layers are modified to make them “orthogonal” to this direction. This means that the model is no longer capable of strongly representing this direction in its activations, effectively disabling its ability to generate refusals based on this learned pattern.
- Model Validation: The abliterated model is tested on a variety of prompts to confirm that it no longer exhibits refusal behavior for requests that would have previously triggered it.
Addressing the Performance Trade-Off
While abliteration can successfully remove the censorship from LLMs, it’s crucial to acknowledge that such modifications can sometimes lead to a performance degradation in other areas. The model might show decreased performance in tasks like:
- Following instructions accurately: It might misinterpret or deviate from the user’s intent.
- Maintaining consistent conversational flow: Responses might be less coherent or relevant to the ongoing conversation.
- Exhibiting general knowledge and reasoning abilities: The model’s ability to access and apply its knowledge might be subtly affected.
This decline likely stems from the fact that safety mechanisms aren’t isolated components; they are interwoven with the model’s overall understanding of language and instructions. Modifying one aspect can have ripple effects on others.
Mitigating Performance Degradation:
One promising avenue for addressing this trade-off involves further training the abliterated model using techniques like:
- Reinforcement Learning from Human Feedback (RLHF): By providing the model with feedback on its outputs and guiding it towards desired behaviors, RLHF can help realign its capabilities with human preferences.
- Data Augmentation and Targeted Fine-tuning: Exposing the abliterated model to a large and diverse dataset of text, potentially with additional fine-tuning on specific tasks, can help it recover lost ground and generalize its abilities.
Case Study: Abliterated Llama 3
The abliteration technique has been successfully applied to various LLM architectures, including the widely used Llama 3 models. Initial versions of abliterated Llama 3 models did exhibit a noticeable performance drop compared to their censored counterparts. However, subsequent refinements and additional training techniques, such as DPO (Direct Preference Optimization), have significantly mitigated this issue.
The result is a new breed of uncensored Llama 3 models that demonstrate state-of-the-art performance on various benchmarks while remaining receptive to a wider range of prompts.
Ethical Considerations
However, we must remember that the ability to remove censorship from LLMs raises significant ethical considerations:
- Misinformation and Harmful Content: Uncensored models could be exploited to generate and spread harmful content, posing risks to individuals and society.
- Bias Amplification: While censorship mechanisms in LLMs are imperfect, their complete removal might amplify existing biases present in the training data.
- Dual-Use Concerns: Techniques like abliteration highlight the dual-use nature of AI research, where methods developed for beneficial purposes can be repurposed for potentially harmful applications.
Conclusion
So, abliteration presents a powerful tool for understanding and manipulating the censorship mechanisms within LLMs. While it offers a glimpse into the inner workings of these complex models, it also underscores the fragility of current safety mechanisms and the ethical tightrope we walk as we develop increasingly powerful AI systems.

Leave a comment