Hugging Face
-

Here I am again with another language model… This time an open source one: Gemma 2, from Google! The world of artificial intelligence has witnessed an explosion in the capabilities of Large Language Models (LLMs)… These complex systems, trained on massive datasets, have demonstrated remarkable proficiency in understanding and generating human-like text, pushing the boundaries…
-
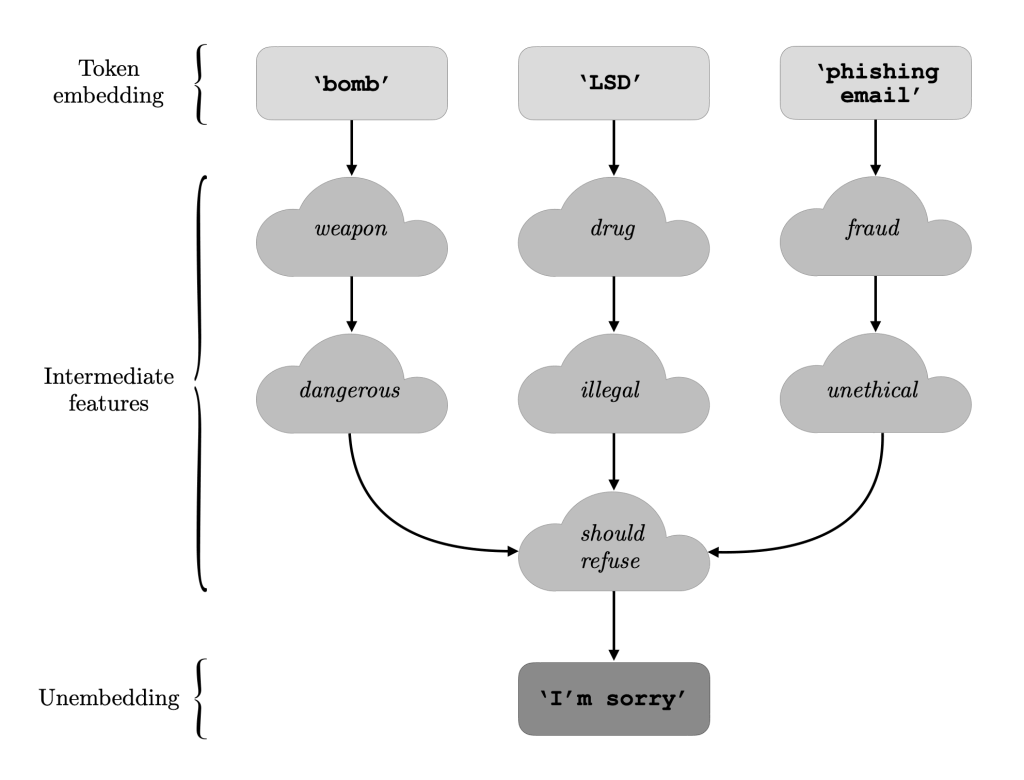
Today let’s talk about the limitations imposed by the built-in safety mechanisms of LLMs: while these safeguards are essential, they often feel like a straightjacket, preventing us from fully exploring the potential of these models. Recently, I stumbled across articles (a paper and an article on Hugging Face) about the concept of “abliteration”, a technique…
-

Let’s face it, when it comes to pushing the frontiers of AI, NVIDIA is right now in a league of its own… And the latest news from NVIDIA is? Nemotron-4 340B: a whole new family of language models where each model is part of a synthetic data generation pipeline able to generate high quality dataset…
-

Stable Diffusion, spearheaded by Stability AI, has become synonymous with accessible and powerful AI image generation. With the release of Stable Diffusion 3 (SD3) the bar for open-source text-to-image generation has been significantly raised. Also, yesterday the weights of Stable Diffusion 3 Medium have been released on Hugging Face, so… It’s time for an article!…
-

Alibaba makes another impactful contribution to the open-source LLM landscape with the release of Qwen2, a substantial upgrade to its predecessor, Qwen1.5. Qwen2 arrives with an array of model sizes, expanded language support, and impressive performance enhancements, positioning it as a versatile tool for diverse AI applications. However, if you want more details go see the…
-

The world of digital content creation is constantly evolving, with a growing demand for personalized and engaging experiences. One area experiencing a surge in popularity is portrait video generation, particularly the ability to generate realistic talking-head videos from a single image. It’s able for example to animate a family photo with a heartfelt message or…
-

The world of text-to-speech (TTS) systems has come a long way. We’ve moved from robotic, flat voices to ones that sound surprisingly human… ChatTTS is a newcomer in this space, and it aims to change the way we interact with computers through natural-sounding speech. Not only, ChatTTS is released under the Attribution-NonCommercial 4.0 International license,…
-

Another model! Yes… This time we have a new Mistral AI’s release: Codestral! This open-weight, 22 billion parameter model is specifically designed to excel in code generation tasks across a vast range of programming languages… But, let’s stop the introduction here. For more details: Multilingual Mastery: Codestral’s Extensive Language Support Codestral boasts an impressive command…
-

Imagine a world where computer vision breaks free from the limitations of rigid, pre-defined object categories, with picture detectors empowered by the richness of language, capable of recognizing objects they’ve never encountered before… This is the world that Grounding DINO 1.5 brings to life, a world where object detection transcends the visual and embraces the…
-

Imagine typing a few lines of text, perhaps a verse from a Tang Dynasty poem or a description of a bustling Hong Kong street market, and watching as a stunningly realistic image materializes on your screen. This is the power of Hunyuan-DiT, a cutting-edge AI model developed by Tencent that excels in generating images from…
