
Large language models (LLMs) have become a cornerstone of artificial intelligence research, capable of generating human-quality text, translating languages, writing different kinds of creative content, and answering your questions in an informative way. Qwen is a series of LLMs developed by Alibaba Cloud’s team of researchers with a focus on both high performance and ease of use and just two days ago a new model of the Qwen series has been released: Qwen1.5-110B, a 110 billion parameter model that tries to push the boundaries of LLM performance (at least of the Qwen series!).
Good! The introduction is finished… More details in the following sections:
- The Foundation: Qwen1.5 Architecture
- Qwen1.5 Series: A Spectrum of Model Sizes
- Multilingual Powerhouse: Global Language Support
- Benchmarking Performance: How Qwen Stacks Up
- Stepping Up the Game: Qwen1.5-110B
- Unlocking Qwen’s Potential: Tools and Frameworks
- The Road Ahead: Qwen and the Future of LLMs
- Conclusion
The Foundation: Qwen1.5 Architecture
The Qwen1.5 series builds upon the Transformer architecture, a prevalent design for LLMs. This architecture employs two key components:
- Encoder: The encoder processes the input text, analyzing the relationships between words and generating a contextual representation.
- Decoder: The decoder utilizes the encoder’s output to generate new text, like translating a sentence or continuing a conversation.
One distinguishing feature of Qwen1.5 models is the use of grouped query attention (GQA). This technique improves efficiency by reducing the computational cost during the attention process, a core step within the Transformer architecture where the model focuses on relevant parts of the input data.
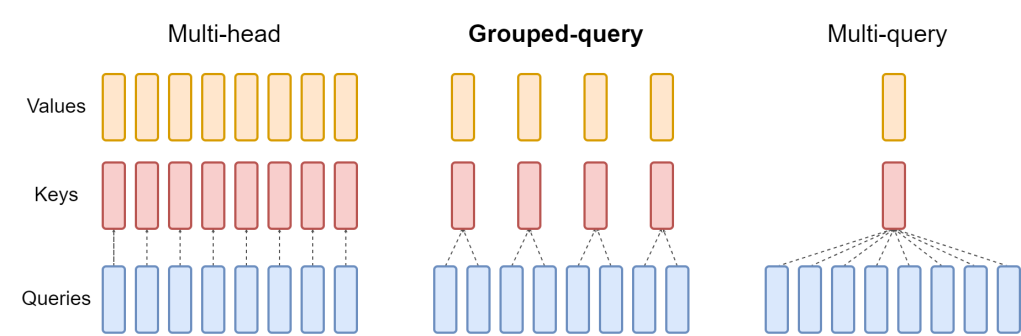
As shown, Multi-head attention has a query, a key, and a value for each head. Multi-query attention shares single key and value heads across all query heads. Grouped-query attention instead shares single key and value heads for each group of query heads.
Qwen1.5 Series: A Spectrum of Model Sizes
The Qwen1.5 series offers a range of models with varying parameter sizes, from 0.5 billion to the recently released 110 billion parameter model (Qwen1.5-110B). This versatility allows users to choose a model that best suits their needs in terms of performance and resource constraints. All models within the series share the same core architecture and functionalities, with the primary difference being the level of complexity achievable due to the varying parameter sizes. Also, Qwen models come in two versions: base models and chat models. Base models are focused on core language understanding tasks, while chat models are fine-tuned specifically for conversational interactions.
Multilingual Powerhouse: Global Language Support
A significant strength of Qwen models is their multilingual capabilities. In fact, these models can process and generate text in numerous languages, including English, Chinese, French, Spanish, and many more like Russian, Korean, Japanese, Vietnamese and Arabic, making Qwen suitable for a broad range of applications requiring real-time multilingual communication or content generation.
Benchmarking Performance: How Qwen Stacks Up
The true test of an LLM lies in its ability to perform well on established benchmarks. Qwen models undergo rigorous evaluation across various tasks, including:
- MMLU: Measures a model’s ability to understand and respond to natural language instructions.
- GSM8K: Assesses performance on mathematical reasoning problems.
- HumanEval: Evaluates a model’s performance based on human judgment of its responses.
- MT-Bench: Specifically designed to benchmark chat models, measuring their ability to engage in informative and coherent conversations.
- AlpacaEval 2.0: Another benchmark for chat models, focusing on factual consistency and reasoning within conversations.
Across these benchmarks, Qwen models have consistently demonstrated competitive performance against other state-of-the-art (at least until April 2024) LLMs. Notably, the recently released Qwen1.5-110B achieves results comparable to the recently released SOTA (state-of-the-art) model, Meta-Llama3-70B, on base model evaluations. More impressively, Qwen1.5-110B significantly outperforms previous Qwen models on chat-specific benchmarks like MT-Bench and AlpacaEval 2.0.
Stepping Up the Game: Qwen1.5-110B
The latest addition to the Qwen family, Qwen1.5-110B, boasts a staggering 110 billion parameters, making it the largest model within the series. This significant increase in parameter size translates to enhanced performance across various tasks. Here’s a closer look at what this new model brings to the table:
- Competitive Base Model Performance: Benchmarking results show that Qwen1.5-110B performs on par with the recently released Meta-Llama3-70B on various base model evaluations. This signifies that Qwen achieves competitive base model performance demonstrates that the model can effectively understand and process language at a level comparable to other leading LLMs. This is crucial because strong base language understanding forms the foundation for all downstream tasks, including chat functionality and creative text generation.
- Superior Chat Performance: While achieving competitive base model performance is noteworthy, Qwen1.5-110B truly shines in the realm of chat interactions. Evaluations on MT-Bench and AlpacaEval 2.0, benchmarks specifically designed for chat models, reveal a significant improvement compared to previous Qwen models (like Qwen1.5-72B). This translates to more informative, engaging, and factually consistent conversations when interacting with the Qwen1.5-110B chat model.
Here’s a table summarizing the benchmark results for Qwen1.5-110B alongside other models for comparison:
| Model | MT-Bench | AlpacaEval 2.0 LC Win Rate |
|---|---|---|
| Llama-3-70B-Instruct | 8.85 | 34.40 |
| Qwen1.5-72B-Chat | 8.61 | 36.60 |
| Qwen1.5-110B-Chat | 8.88 | 43.90 |
Higher scores in MT-Bench and AlpacaEval 2.0 indicate better performance. LC (Length-controlled) Win Rate refers to the win rate in a task where the model needs to predict the missing word in a sentence.
The improvements in chat performance suggest that scaling the model size (from 72B to 110B parameters), obviously, leads to better conversation abilities even without drastic changes to the fine-tuning process used to train the chat model specifically… What a discover! However, let’s see how it performs against other models.

Not bad, right?
Unlocking Qwen’s Potential: Tools and Frameworks
A core principle behind the Qwen series is to make these models accessible and easy to use for developers and researchers. The team provides comprehensive documentation and supports integration with various frameworks and tools, enabling users to leverage Qwen’s capabilities seamlessly within their projects. Here’s a glimpse into the available options:
- Hugging Face Transformers: This popular deep learning library allows users to load and utilize Qwen models with minimal code.
- vLLM: This framework facilitates deploying Qwen models as an OpenAI API-compatible service, enabling easy integration into existing applications.
- llama.cpp: This tool provides efficient inference for Qwen models on CPUs and GPUs, allowing users to run Qwen models locally for tasks like question answering or text generation.
- Ollama: This user-friendly command-line tool allows running Qwen models with a single line of code, making it ideal for quick experimentation and testing.
- LLaMA-Factory and Axolotl: These advanced training frameworks enable researchers to fine-tune Qwen models for specific tasks or even train entirely new models based on the Qwen architecture.
This diverse range of tools and frameworks empowers users with varying levels of technical expertise to leverage the power of Qwen models in their projects.
The Road Ahead: Qwen and the Future of LLMs
The release of Qwen1.5-110B signifies a significant milestone in the development of the Qwen series. This model pushes the boundaries of LLM performance while maintaining a focus on usability and efficiency. Looking ahead, the team behind Qwen is actively exploring several exciting avenues for further development:
- Scaling Both Data and Model Size: The success of Qwen1.5-110B highlights the potential of scaling model size for performance gains. However, the team also acknowledges the importance of data quality and size in LLM training. Future iterations may explore scaling both data and model size to achieve even greater performance leaps.
- Qwen2: The Next Generation: The team is hinting at a future generation of Qwen models, tentatively named Qwen2. This suggests potential architectural advancements or even a completely new approach to building LLMs.
For the moment, you can test Qwen1.5-110B with this HuggingFace demo.
Conclusion
These developments promise even more powerful and versatile LLMs in the near future. Qwen, with its focus on usability and a strong developer ecosystem, is well-positioned to play a leading role in shaping the future of language models and their impact on various industries and applications.

Leave a comment